It's been two years since we published the post Cloud-Scale Text Classification with Convolutional Neural Networks on Microsoft Azure. In that post, we discussed an interesting approach to NLP, using CNNs.
This idea was shared across two papers: Char-CNN (also called Crepe) and VDCNN, which became the state of the art at the time of their publication.
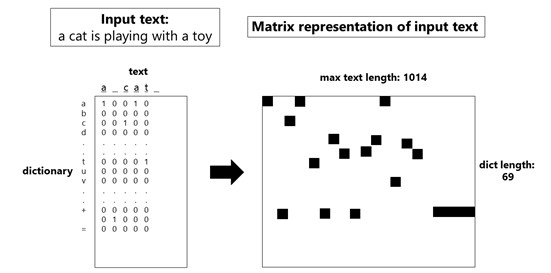
The key idea is to encode each sentence as an image-like matrix, where each encoded character is equivalent to a pixel in the image. As it can be seen in the previous figure, the rows correspond to a dictionary and the columns correspond to the characters in the sentence.
The dictionary consists of 69 letters, numbers and symbols and the sentence is a one-hot encoded vector, that is, for each letter in the column, we assign a 1 to the corresponding dictionary letter in the row. The length of the sentence is fixed at 1014 characters, longer sentences are trimmed down and shorter sentences are padded with spaces.
Once the matrix is computed, it is possible to apply the convolutions. Crepe combines convolution, activation and pooling layers while VDCNN uses also residual layers.
Two years ago, we shared the code for these models, but the repo was deleted and since then we have been asked many times to make the code available again. This is what we did on this repo where you can find the Crepe and VDCNN models in Python and R.
A final word about new advancements on NLP. Character convolutions have been replaced by the new Transformer architecture, becoming the state of the art. Newer models like GPT-2, MT-DNN, Transformer-XL or BERT have push yet again the borders of science forward.