Why Deep Learning
Deep learning is the key technology that is revolutionizing AI. For the first time in history, a computer is able to surpass human intelligence in some tasks that were very difficult to solve before. These tasks are related to generalization, which is one of the most advanced human intelligence features and one of our main differences with animals.
One recent example is object recognition. In 2015 a Convolutional Neural Network (CNN) designed by Microsoft, named ResNet, was the first system to surpass the human performance level in the computer vision competition ImageNet. In this competition, the system has to correctly identify an object among 1000 categories. ResNet, a CNN composed of 152 layers, was able to achieve a top 5 error of 4.94%, slightly better than a trained human. Since then, other architectures have achieved better results.
Another recent achievement of CNN was the system AlphaGo, designed by DeepMind (Google). It became the first computer program to defeat a professional player in the game of Go, a strategy game similar to chess but much more difficult.
Deep learning can be applied to many problems: image understanding, natural language processing, risk detection, recommendation system, financial forecasting and many more. However, current CNNs needs millions of examples to train and lots of computational power to run. The curious thing is that we were able to surpass parts of human intelligence without imitating human intelligence. Humans don't need millions of examples to recognize an object in an image. Nevertheless, deep learning is so promising and attracts so much interest for one simple reason: it is the best bet we currently have to solve artificial intelligence.
What is a CNN
CNN are a key resource in deep learning. They are based on a mathematical operation called convolution. A convolution is just a multiplication of an input image (which is a matrix) times a kernel (which is another matrix). This operation generates a different image as it can be shown next, where a kernel called Sobel has been applied over the Y axis. The output image enhances the borders in the Y axis (normally, in computer vision, the X axis corresponds to the height and the Y axis to the width).

Therefore, the key advantage of convolutions is that they produce new images, related to the original one, that enhance different areas of the input. They are featuarizers, automatic feature generators. And that is the key concept that makes deep learning so powerful.
A CNN is a neural network with many hidden layers that use convolutions to generate features hierarchically. The first layer or input layer convolves the input image to another set of images, usually called feature maps, generating a different representation of the input. The second layer, or first hidden layer, convolves the first feature maps to another set of feature maps, which are representations of the first hidden layer, and so on until we reach the output layer. Finally, we obtain a hierarchical structure where each layer contains images that are representations of the previous ones.
Character recognition
Let's see an example of how a CNN can recognize handwriting characters. MNIST dataset contains a training set of 60,000 examples and a test set of 10,000 examples of handwriting characters. It is one of the most famous datasets of character recognition and was very popular in the 2000s.
In 1998, Prof. Yann LeCun, now the head of Facebook Research, published a CNN that achieved a 99% accuracy in the task of character recognition using MNIST dataset. He named the architecture LeNet. LeNet architecture uses convolutions and pooling operations to increase performance. For many years, LeNet was the most accurate algorithm for character recognition and supposed a great advance in deep neural networks, long before the appearance of GPUs and CUDA.
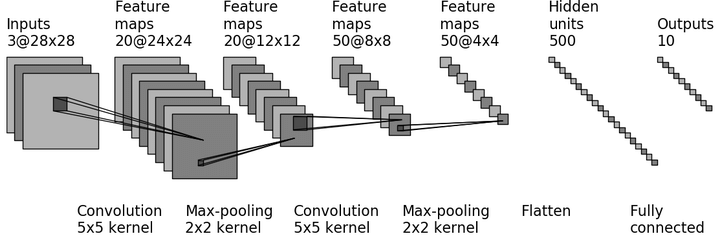
As can be seen in the following image, LeNet has several groups of hidden layers. The original image is first transformed using convolutions into $c_1$ that has 20 feature maps. These feature maps are the hierarchical representations that we were talking about before. Next, there is a pooling operation, $p_1$, this operation produces a dimensionality reduction, to decrease the number of parameters to optimize. Afterwards, there is another group of convolution and pooling, $c_2$ and $p_2$. Here the number of feature maps is 50. Finally, there are two fully connected layers, $fc_1$, that has 500 units and $fc_2$ that has 10. A fully connected layer is a layer with all the units connected to each other. It is usually added at the end of the network. The second fully connected has 10 units corresponding to the 10 outputs of MNIST dataset, from 0 to 9.
If you are into coding, I created a jupyter notebook with a tutorial on how to train CNN. It is written in python and uses OpenCV and MXNet libraries. It explains how to create simple convolutions and how to train the LeNet architecture on MNIST dataset.
If you want to go deeper in knowing how CNN work, check out this video of my colleague Brandon Rohrer from Microsoft.