Distributed Training
With more and more data being created every day, we need more computational resources to create AI. Distributed training is a scalable solution to this problem.
There are 2 general methodologies to perform distributed training: data parallelism and model parallelism.
In data parallelism, we copy the entire model on each worker, processing different subsets of the training data set on each.
In model parallelism, different machines in the distributed system are responsible for the computations of different parts of a single network, for example, each layer in the neural network may be assigned to a different machine.
Data parallelism is easier to implement, stronger to fault tolerance, and has higher utilization of GPUs. On the other hand, model parallelism has better scalability of large models and it uses less GPU memory.
Generally speaking, data parallelism is more common, but some people even use a combination of the two techniques.
DeepSpeed
Being able to train machine learning models in a distributed fashion has always been a pain. In contrast to Spark systems, which automatically leverages a distributed infrastructure on top of the JVM, computing deep learning on multiple GPU clusters with Python and CUDA is complex. DeepSpeed aims to facilitate this task.
DeepSpeed is an open-source library that facilitates model development and training in a distributed mode.
The library is a light wrapper on top of PyTorch. With minimal code changes, a developer can train a model on a single GPU machine, a single machine with multiple GPUs, or on multiple machines in a distributed fashion.
One of the advantages is that it enables massive models. When the library was first released, it was able to train a model of 200B parameters, by the end of 2021, the team was able to train Megatron-Turing NLG 530B, the largest generative language model to date with 530 billion parameters. They are working to support soon a model of 1 trillion parameters.
The other important feature is its speed. According to their experiments, DeepSpeed trains 2–7x faster than other solutions by reducing communication volume during distributed training.
Last, but not least, the library only requires minimal code changes to use. In comparison to other distributed training libraries, DeepSpeed does not require a code redesign or model refactoring.
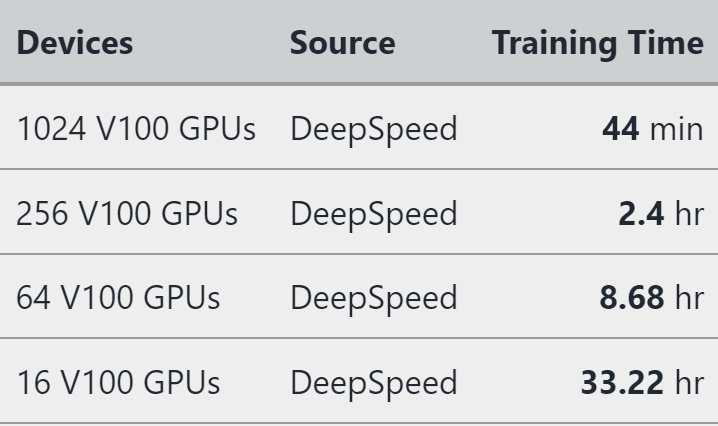
In the following table, the authors show the training time of BERT-large.
Training API
The core functionality of DeepSpeed comes from its engine. This engine can wrap any model in the form of torch.nn.module with a minimal set of code changes for training and checkpointing the model.
DeepSpeed model training is accomplished using the DeepSpeed engine. The engine can wrap any arbitrary model of type torch.nn.module and has a minimal set of APIs for training and checkpointing the model.
The three main components are the initialization, with initialize method, the training, with backward and step methods, and checkpointing, with load_checkpoint and save_checkpoint.
The method initialize sets up of the model, training optimizer, data loader, and the learning rate scheduler. It also initializes the engine for distributed data parallel or mixed precision training.
model, *_ = initialize(args=cmd_args,
model=model_architecture,
model_parameters=params)
After the engine is initialized, we can train the model with three small changes in the standard PyTorch API: forward propagation, backward propagation, and weight updates.
for step, batch in enumerate(data_loader):
# Forward propagation method
loss = model(batch)
# Runs backpropagation
model.backward(loss)
# Weights update
model.step()
DeepSpeed can automatically save and restore the model, optimizer, and the learning rate scheduler states via the save_checkpoint and load_checkpoint.
Zero Redundancy Optimizer
The Zero Redundancy Optimizer (ZeRO) is the key component that allows DeepSpeed to train massive models at scale. ZeRO enables the training of models with over 13 billion parameters without model parallelism, and of models with more than 500 billion parameters using model parallelism.
At the time of writing, ZeRO has gone through 3 iterations, being ZeRO-3 the latest version. ZeRO optimizes the memory consumption by partitioning the weights, gradients, and optimizer components of the model across the CPUs and GPUs of the distributed system.
To get a quick start on DeepSpeed, see this short tutorial where it is explained how to quickly transform a PyTorch model to add the DeepSpeed capability.