The Transformer architecture is the AI model responsible for the significant advancement in NLP in the last few years.
Its main component is the self-attention mechanism, which learns the importance of each part of the sentence in relation to a word. For example, in "The animal didn't cross the street because it was too tired", self-attention associates "it" with "animal".
However, self-attention is very heavy to compute, it scales with quadratic complexity with respect to the sentence length.
A new solution proposed by Google, FNet, replaces self-attention with a Fourier transform, which is only 8% less accurate than BERT in the GLUE benchmark but 7 times faster to compute in a GPU.
The Fourier transform is a mathematical operation that transforms a complex temporal signal, into simpler subcomponents defined by a frequency. This operation can be applied to a sentence inside the Transformer architecture as a replacement of the self-attention mechanism. Intuitively, applying a Fourier transform is just encoding the input as a linear combination of the text embeddings.
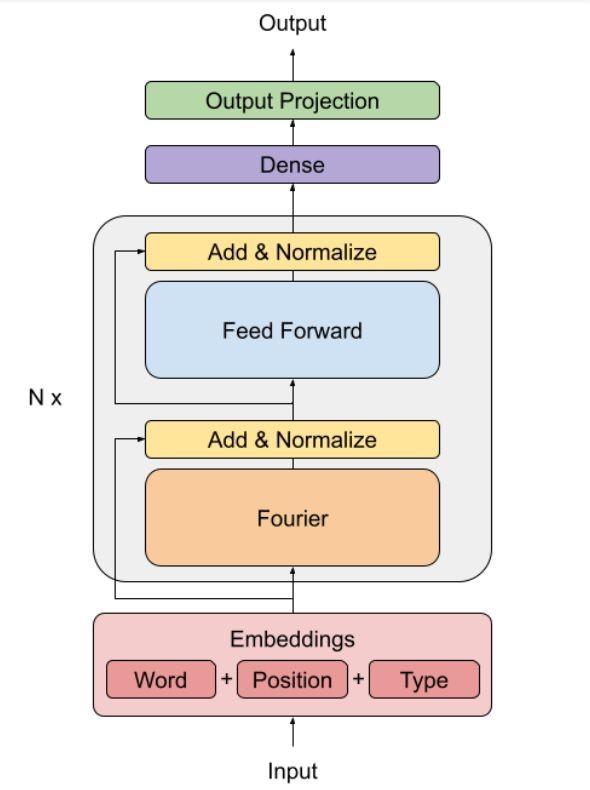
These linear combinations are mixed with simple non-linearities in the feed-forward network. The result is a faster Transformer that is able to competitively understand the semantic relationship in the text in several NLP tasks.
The question this paper suggests is, do we really need complex non-linearities?