Recommendation Systems
Recommendation systems have become increasingly popular in recent years, in parallel with the growth of internet retailers. These systems are used in a variety of areas including movies, music, news, books, search queries, and products in general. In terms of business impact, according to a recent study from Wharton School, recommendation engines can cause a 25% lift in the number of views and 35% lift in the number of items purchased. So it is worth understanding these systems.

Generally speaking, there are 3 methodologies for recommendation systems: collaborative filtering, content-based filtering and hybrid recommender systems.
Collaborative filtering collects large amounts of information on users’ behavior in order to predict what users will like based on their similarity to other users. This information can be explicit, where the user directly provides the ratings of the items, or implicit, where the ratings must be extracted for the implicit user behavior, like number of views, likes, purchases, etc.
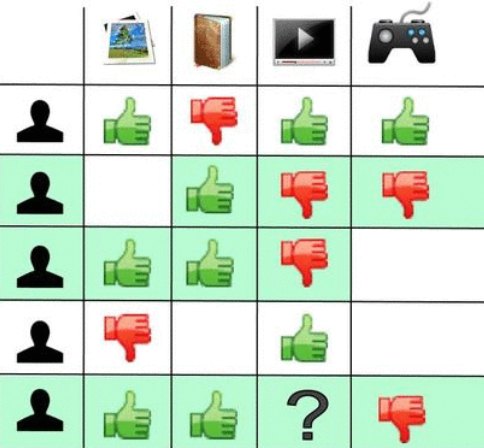
Mathematically, it is based on inferring the missing entries in an $m\times n$ matrix, $R$, where elements $(i, j)$ describe the ratings given by the $i_{th}$ user to the $j_{th}$ item. The performance is then measured using Root Mean Squared Error (RMSE). This problem has been addressed in a variety of ways. Traditional methods include low-rank matrix factorization like Alternating Least Squares, which became popular due to its implementation in Spark. Methods based on Deep Learning have grown in popularity recently, some techniques use embeddings and RELU activations like in Youtube, recurrent neural networks like in (Hedasi et al., 2016) or deep autoencoders like the this tutorial.
Content-based filtering take into account contextual user factors such as location, date of purchase, user demographics and item factors like price, brand, type of item, etc, to recommend items that are similar to those that a user liked in the past.
The system creates a content-based profile of users based on a weighted vector of item features. The weights denote the importance of each feature to the user and can be computed from individually rated content vectors using a variety of techniques. Simple approaches use the average values of the rated item vector while other sophisticated methods use machine learning techniques such as Bayesian classifiers, decision trees, and neural networks to estimate the probability of a user liking the item.
Hybrid recommender systems combine multiple techniques together to achieve some synergy between them. They can use aspects from collaborative filtering, content-based filtering, knowledge-based and demographics. They have proved to be very effective in some cases, like the Bellkor solution, winner of the Netflix prize, the Netflix Recommender System or LightFM.
Deep Autoencoder for Collaborative Filtering
A current state-of-the-art model, developed by NVIDIA, is a 6 layers deep autoencoder with non-linear activation function (SELU - scaled exponential linear units), dropout and iterative dense refeeding.
An autoencoder is a network which implements two transformations: $encode(x) : R^n \Rightarrow R^d$ and $decoder(z): R^d \Rightarrow R^n$. The “goal” of an autoencoder is to obtain a lower $d$ dimensional representation of data such that an error measure between $x$ and $f(x)=decode(encode(x))$ is minimized.
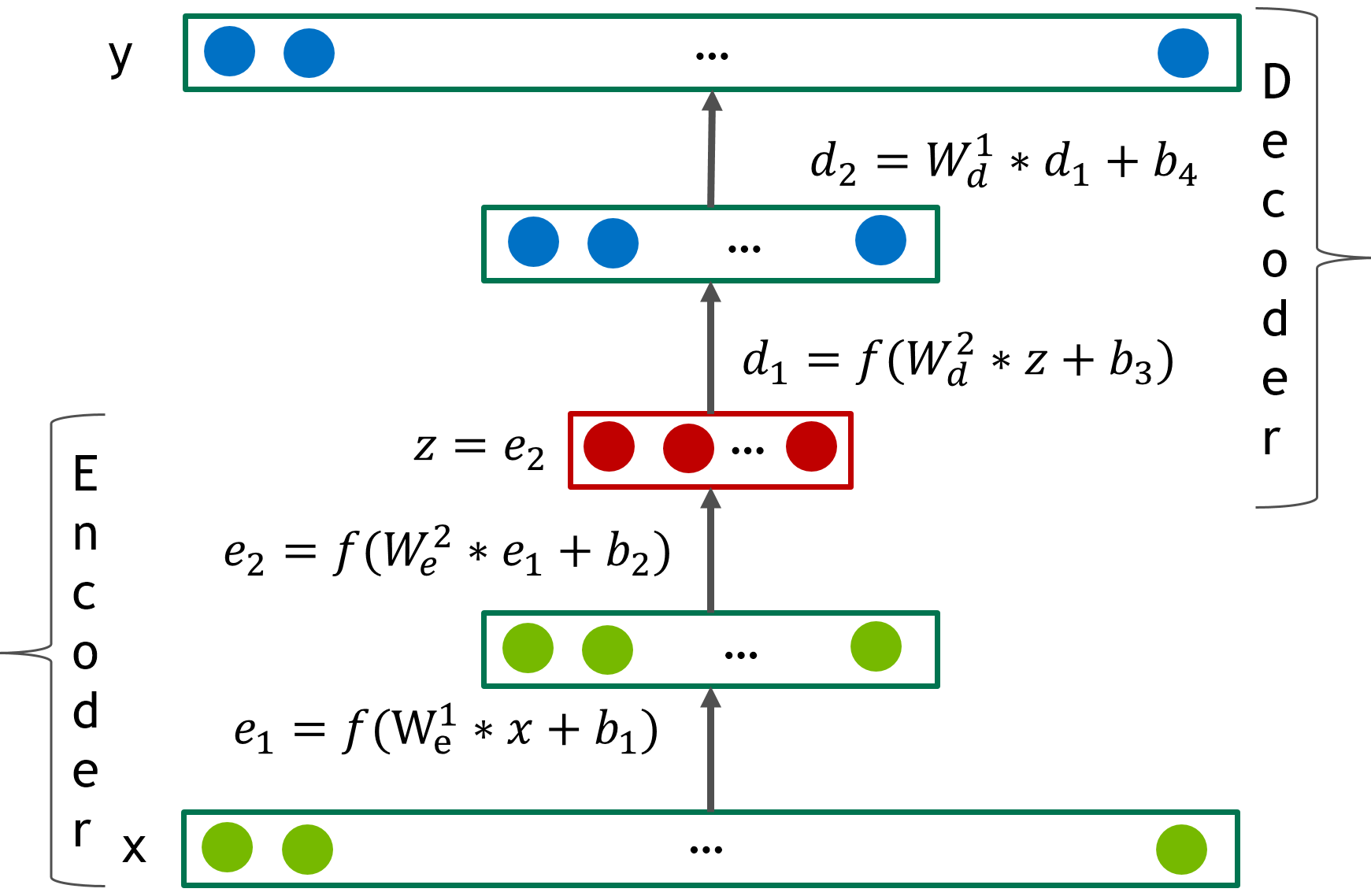
During the forward pass, the model takes a user representation by his vector of item ratings from the training set $x \in R^n$, where $n$ is number of items. Note that $x$ is very sparse, while the output of the decoder, $y=f(x) \in R^n$ is dense and contains the rating predictions for all items in the corpus. The loss is the root mean squared error (RMSE).
One of the key ideas of the paper is dense re-feeding. Let's consider an idealized scenario with a perfect $f$. Then $f(x)_i = x_i ,\forall i : x_i \ne 0$ and $f(x)_i$ accurately predicts all user's future ratings. This means that if a user rates a new item $k$ (thereby creating a new vector $x^\prime$) then $f(x)_k = x^\prime_k$ and $f(x) = f(x^\prime)$. Therefore, the authors refeed the input in the autoencoder to augment the dataset. The method consists of the following steps:
- Given a sparse $x$, compute the forward pass to get $f(x)$ and the loss.
- Backpropagate the loss and update the weights.
- Treat $f(x)$ as a new example and compute $f(f(x))$
- Compute a second backward pass. Steps 3 and 4 can be repeated several times.
Finally, the authors explore different non-linear activation functions. They found that on this task ELU, SELU and LRELU, which have non-zero negative parts, perform much better than SIGMOID, RELU, RELU6, and TANH.
If you want to see this model in practice, take a look at this notebook, where we create a recommender system with the Netflix dataset and an API to operationalize it.