Why Transfer Learning?
According to Andrew Ng, cofounder of Coursera and Adjunct Professor at Stanford, Transfer Learning will be the next driver of Machine Learning commercial success.
Transfer Learning is a Machine Learning technique that allows to reutilize an already trained convolutional neural network (CNN) on a specific dataset and adapt it, or transfer it, to a different dataset. The reason you want to reuse a trained CNN is because they take a long time to train. For example, training ResNet18 for 30 epochs in 4 NVIDIA K80 GPU took us 3 days. Training ResNet152 for 120 epochs in the same GPUs takes 4 months.
In this post we used PyTorch to perform transfer learning in different datasets. If you are in a hurry, just go directly to the code.
Transfer Learning Strategies
In general, there are two strategies to perform transfer learning, and I have not seen a final agreement on the naming. Finetuning, which consists of using the pretrained network on the base dataset and train all layers in the target dataset, and freeze and train, which consists of leaving all but the last layer frozen (the weights are not updated) and train the last layer. It is also possible to freeze the first couple of layers and finetune the rest, this is due to some evidence indicating that the first layers of the CNN contains texture filters and color blobs.

However, in this work we are going to analyze the two extreme cases: training all layers and training only the last layer.
The most common base dataset is ImageNet, which contains 1.2 million images with 1000 categories. These categories are divided in two big groups: animals and objects. The number of images per category is around 1000. Most deep learning libraries provide CNN models pretrained on ImageNet.
In the image, we can see the two mentioned transfer learning strategies. Here we used a pretrained CNN on ImageNet and adapt it to classify Homer Simpson, using as the target dataset a subset of the Simpsons Dataset. This subset contains 20 classes with between 300 and 1000 images per class.
Then we can use freeze and train, as it is represented in the upper figure, and just train the last layer, or we can finetune all layers, as it is represented in the bottom figure.
Finetuning vs freezing
It is difficult to know in which cases one should just train the last layer or finetune the network. In (Yosinsky et. al., 2014), the authors address the problem of quantifying the degree to which a particular CNN layer is general or specific in the context of the ImageNet dataset. They found that the transferability is negatively affected by splitting the network in the middle layers due to coadaptation of these layers. They reported that the transferability gap grows as the distance between tasks increases and finally, they found that initializing the network with transferred weights can improve generalization performance in comparison with training it from zero weights.
As reported in this tutorial of Karpathy, these are some guidelines of the different scenarios when using transfer learning in a new dataset:
- Small and similar images: When the target dataset is small in comparison with the base dataset and its images are similar, the recommendation is to freeze and train the last layer.
- Large and similar images: In this case the recommendation is finetuning.
- Small and different images: In this case the recommendation is freezing and train the last layer or some of the last layers.
- Large and different images: In this case the recommendation is finetuning.
In the experiments, we used a limited number of datasets with a small network, ResNet18, so it will be premature to generalize the findings to all datasets and networks. However, the findings may shed some light on the problem of when to use transfer learning. In the following table there is a summary of the results.
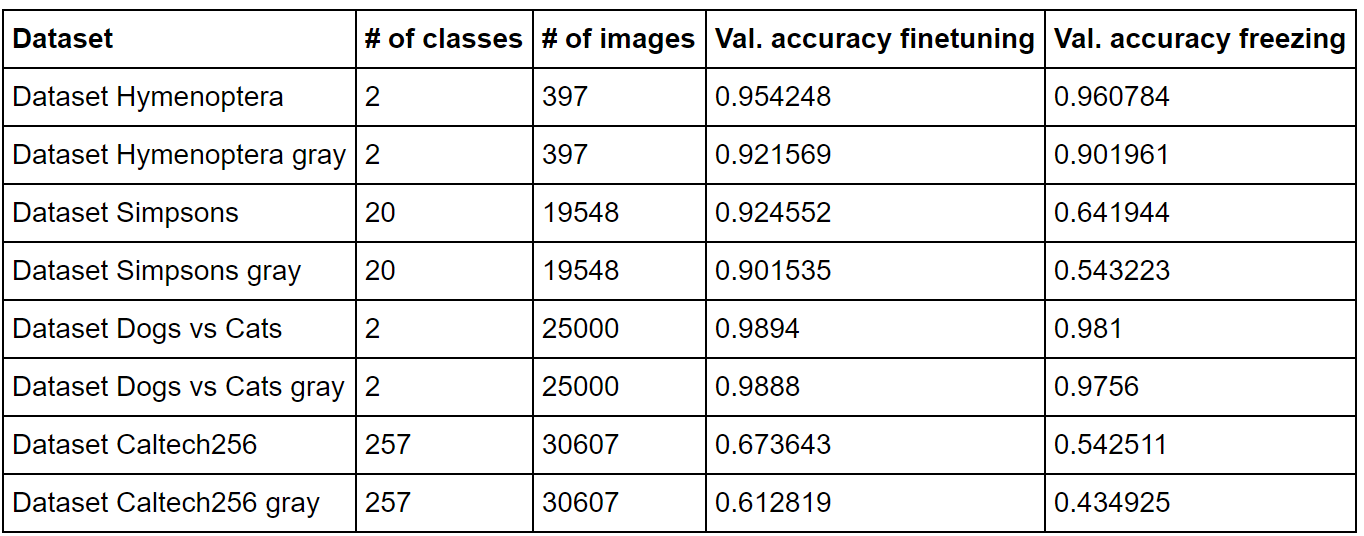
The first detail we observe is an accuracy degradation when training a gray scale dataset in comparison with its color scale counterpart. This is consistent with the observation of other authors that the more different the domain between the base dataset and the target dataset, the worse the transference.
We see as well that for Simpsons and Caltech256 datasets there is a high degradation when freezing. The highest degradation can be appreciated in Simpson dataset, which can be due to the fact that the domains are quite different, while in ImageNet there are natural images, in Simpsons the images have mostly plain colors. In Caltech we observe firstly a low accuracy, apart from a high degradation when freezing. Maybe the reason is because for a dataset of a high number of classes, the number of images per class is small, in the order of a couple of houndreds.
The domain of dogs vs cats dataset is the closest to ImageNet, in fact, ImageNet contains several breeds of dogs and cats. In this case, there is no much difference when finetuning or freezing.
Finally, in the hymenoptera dataset, we see a small improvement in the color dataset when freezing. This can be because the domain is closer and the dataset is small. In the grayscale counterpart we don't see an improvement when freezing, probably due to the domain difference.