Natural Language Processing
Natural Language Processing (NLP) is the area of machine learning that studies the generation and understanding of language, both in writing and speaking. Its main objective is to create machines able to understand and communicate with us in a natural way.
Some subareas of NLP are machine translation, speech recognition, topic modeling, Q&A, information retrieval, optical character recognition (OCR), text classification and sentiment analysis. Of all of them, machine translation is my favorite, it consists of automatic translation between different languages, like the Babel fish in a Hitchhiker's Guide to the Galaxy. A technology like this will, hopefully, reduce the hate between people speaking different languages, but maybe I'm a dreamer. Speech recognition has to do with recognizing spoken language. In this area, there was an important advance in October 2016, when Microsoft Research achieved human parity in conversational speech recognition. Topic modeling is used to extract the topics in a document and it is generally used in text mining to discover similarities between documents. Q&A took a good deal of relevance thanks to IBM Watson and its victory in Jeopardy. Now this area is extensively used by companies in their customer services. Information retrieval is at the core of one of the most profitable business in the world, Google. OCR has the objective to provide a machine with reading capabilities.
Text Classification
In this post, I will focus on text classification and sentiment analysis. Text classification, also called topic classification, is a methodology to categorize pieces of text into classes. It has a very interesting business application that some companies are taking advantage of. When a customer communicates with the company asking for a service or just for customer support, the system has to redirect the customer to the correct department (or even to the final solution). In that situation, a text classifier can save a lot of money.
A very interesting business application of text classification is sentiment analysis. It is a method to automatically understand the perception of customers towards a product or service based on their comments. The input text is classified into positive, negative, and in some situations, neutral. It is extensively used by companies to track user behavior on Twitter. Sentiment analysis can strongly influence the marketing strategy of a company, improving the customer experience and defining the advertising roadmap.
In this notebook, I give a tutorial on how to quickly implement text classification in python using fastText library. Using DBPedia dataset we can classify a sentence like the following:
Sentence: One of my favourite tennis players in the world is Rafa Nadal.
Label: 4; label name: Athlete; certainty: 0.904297
As can be seen, the model classifies the sentence as Athlete with a certainty of 90.429%.
Word Featurization
Most text classification techniques use some kind of word featurization. It transforms the text into a numeric representation. This numeric representation allows machine learning algorithms to easily computing models using the words or characters as inputs. Two notable techniques are bag of words and word embedding.
Bag of words consists of computing the frequency of each word in the text as a histogram. Sometimes, instead of getting the frequency of single words, you can compute the method for pairs of words, often referred to as bi-grams, or triplets of words referred to as tri-grams. The general case is called n-grams. Once the text is mapped as a histogram, other techniques can be applied. One example is text comparison, the bag of words of two sentences can be computed and subsequently compared using a metric like quadratic difference or Kullback-Liebler divergence.
Word embeddings was an idea introduced by Bengio in 2001. Basically, the method maps each word to a high dimensional vector of perhaps 50 to 300 dimensions. The algorithm learns simultaneously a distributed representation for each word along with a probability function for word sequences. Therefore the method can understand that the sentence "the cat is playing with a toy" and "the cat is playing with an object" are equivalent and have a high probability to be consistent. However, in the sentence "the cat is flying with a toy", the method would produce a low probability. Of all word embedding algorithms, maybe the most popular is word2vec created by Mikolov.
Another property of word embeddings is that we can compute the similarity between words, as we did in the notebook (in the word representations section). In the multidimensional space, the difference between king and queen, 12.58, will be smaller than between king and woman, 20.16. Makes sense, right? At the same time, the difference between king and queen will be similar to the difference between man and woman, 11.27.
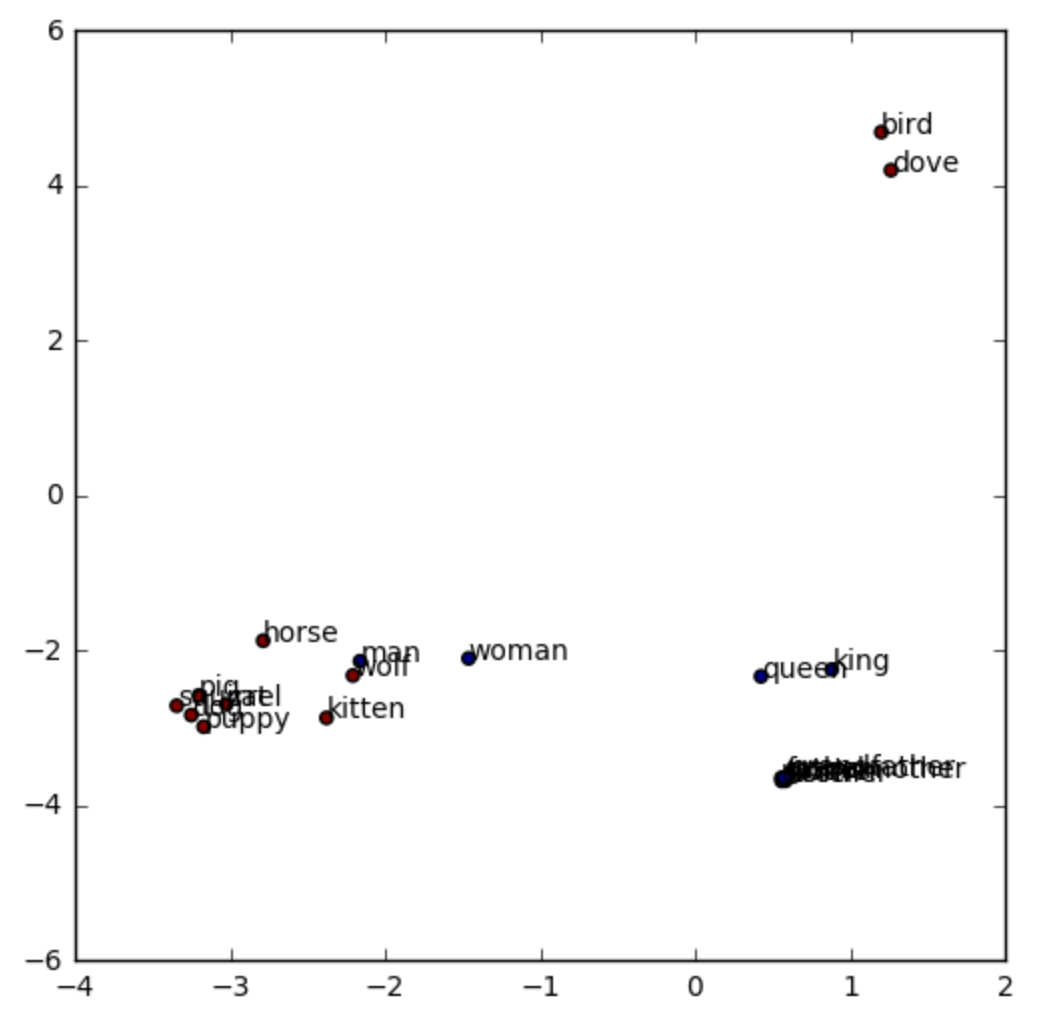
Finally, we can represent the words in a reduced dimensional space. For that, we used the t-SNE algorithm. The results can be visualized in the section word space visualization of the notebook. After the computation, we can see that the words bird and dove are clustered together, also sister and brother, and mother and father.