What is math
Before starting to address the subject of Machine Learning, it is essential to understand first what is mathematics and why it is so important. Math is the language of science. It allows scientist and engineers to express the Universe and the phenomenons that happen inside it.
Like any language, it has tenses: past, present and future, so we can explain what happened in the past, we can describe what is happening in the present, and we can predict what will happen in the future. The most useful tense in math is the future, i.e. the prediction of events.
We are very interested in predicting the future, or knowing how a system will evolve over time starting from an initial state. We can predict the future trajectory of a meteorite to know if it will hit the Earth (so we can call Bruce Willis) or we can predict the sales of a product in Amazon (so we can make Jeff Bezzos happy). Anyhow, predicting is important. and Machine Learning is a really good way of predicting things.
In order to play with math, we need numbers and variables (which are just letters that represent different values). These numbers and variables create the most important mathematical resource to talk about the Universe, the model. A model is just an equation that represents a concept or event in the mathematical language. Some famous models are $x^2+y^2=r^2$, which means a circle of radius $r$; $F=ma$, also known as Newton's Second Law of Motion, it states that the force, $F $, is proportional to the acceleration, $a$, in a quantity called mass, $m$; or the famous Einstein equation $E=mc^2$, which states that all mass, $m$, has an amount of energy, $E$, proportional to the square of the speed of light, $c$.
There are two kinds of models, analytical models, like the ones previously mentioned and learned models. Until the computer era, most scientists used analytical models, mainly because in order to develop learned models it is necessary to compute many operations. Other significant difference between analytical and learned models is that, usually, analytical models are derived using a mathematical demonstration, which is a set of steps that reach a final equation. On the contrary, learned models are obtained via a process called training or optimization, and need many examples of inputs-outputs pairs to obtain the equation. For this reason, analytical models tend to be compact and beautiful equations, while learned models tend to have hundreds of parameters, generating very complex and large equations.
What is Machine Learning
Machine Learning is a technique that allows obtaining learned models to generate predictions. It has a huge advantage in comparison with analytic models, you don't need to derive a formula, therefore you don't really need to have a deep understanding of math.
The only thing you need to have is a group of input and output pairs. The model is just the relationship between inputs and outputs.
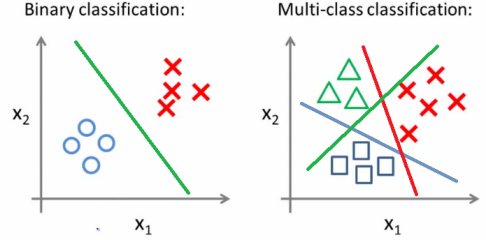
In the image, the inputs correspond to the points $(x,y)$, the outputs are the color red and blue, meaning that the inputs are divided into two different classes, and the model is the line that divides both classes. This specific problem is called classification.
The model we obtained follow this equation, $y=wx+b$, where $w$, is the slope, and $b$ is the bias, they are both numbers. The equation could be something like: $y=-1.3x+1.6$
Once we have the model, we can make predictions. For example, given a new input point $(x,y)=(0.2,0.3)$, what would be the output? If the new point is below the line, it will belong to the output blue, otherwise, it will be red. We can also have a multi-class classification problem, as shown in the picture.
The concept of optimization
The last key concept to understand is optimization, which in the machine learning nomenclature is called training.
To explain the concept of optimization let's imagine a football player taking a penalty like in the next image. The player hits the ball with the intention that it follows a trajectory that ends up in goal, but many times the ball doesn't follow the trajectory the player desired. So there are two trajectories, the desired one and the actual one.

Optimization is the process of tuning the parameters of the model to make the desired and the actual output as similar as possible. The parameters of the model, in the case of the previous equation, are $w$ and $b$. The difference between the desired and actual output is called the error. Therefore, optimization is equivalent to minimize the error.
The training process of a machine learning algorithm is the optimization of the parameter's model so the desired output (which is the output we know from the data), and the actual output (which is the output predicted by the model equation) are as similar as possible. This process is simulated in the first image, when the line is moving. Initially the line doesn't divide the classes very well, there is a high error. Later, as the parameters change, the line divides the classes perfectly, reaching a minimal error.
There are many ways to train a machine learning model, such as gradient descent or genetic algorithms, and there are many different algorithms, such as support vector machines, neural networks or random forests. But they all follow the same basic principles addressed in this post. All this compose the big world of machine learning algorithms.